大規模言語モデルによる文献スクリーニングの効率化―診療ガイドライン作成におけるAIの活用―
国立大学法人千葉大学
千葉大学医学部附属病院 救急集中治療医学の大網毅彦講師、同大学院医学研究院の中田孝明教授、国立シンガポール大学 Duke-NUS Medical Schoolの岡田 遥平研究員らの研究チームは、ChatGPTなどの大規模言語モデル(LLM: Large Language Model)(注1)を診療ガイドライン作成の一部に用いることで、ガイドライン作成に必要な文献を膨大な医学情報の中から高い精度で見つけ出すことができることがわかりました。同時に、医学文献検索にかかる膨大な作業時間を従来の方法の10分の1以下まで短縮できることも明らかになりました。
医師や看護師などの医療従事者が中心となって作成する診療ガイドラインには多くの人手や時間が必要です。現在、医師の働き方改革(注2)が進められており、医療従事者の労働負担を減らすことが重要な課題となっています。AIを活用した効率的な文献スクリーニング方法は、持続可能な働き方を実現するための一つの解決策として期待されます。
日本版敗血症診療ガイドライン(注3)2024作成委員会の取り組みの一環として行われた本研究成果は、総合医学雑誌JAMA Network Openに2024年7月8日(現地時間)に掲載されました。

■研究の背景
診療ガイドラインは、ある疾患に対する検査や治療を決めるための道標として医療従事者や患者さんが参考にする文書です。このガイドラインを作成するために必要なシステマティックレビューという作業は、ある医学領域に関連する文献を抽出し、文献の情報を同定、選択や評価を行う作業で、多くの労力や時間を要します。一方、人工知能(AI)の一種であるChatGPTなどのLLMは学習した大量のデータをもとに、人間が指示した命令や質問に答えることができます。このLLMが、システマティックレビュー作業の中でも特に多くの労力を要する文献の抽出作業を代わりに行うことができれば、人間が行うべき作業量を大幅に削減することができます。しかしこれまで、LLMを用いた文献スクリーニング作業の精度や作業負担軽減の程度は検討されていませんでした。
本研究では、日本版敗血症診療ガイドラインの作成において、LLMを用いた文献スクリーニングの精度と効率性を評価しました。
■研究内容と結果
本研究は、診療ガイドラインの中から5つの臨床疑問(CQ)に関する文献スクリーニングデータを使用して、LLM(OpenAIより2023年11月7日に公開されたGPT-4 Turbo)がそれぞれのCQに関連するキーワードをもとに抽出された数多くの文献の中から、CQに含まれる患者/集団/問題、介入、比較、および研究デザインに合致する文献を正確に選び出すことができるかどうかを検証しました。LLMの文献スクリーニングの正確性を評価するために、ガイドラインメンバーが実際に行った文献スクリーニングの結果をゴールドスタンダード(注4)として、LLMを使用した文献スクリーニングの結果を評価しました。具体的な正確性の指標として、感度(注5)と特異度(注6)を計算しました。また、従来のスクリーニング方法とLLMを用いたスクリーニング法の作業時間を比較しました。
1.大規模言語モデルを用いた文献スクリーニングの正確性
・従来の文献スクリーニング方法では、CQ1で5,634件中8件、CQ2で3,418件中4件、CQ3で1,038件中4件、CQ4で4,326件中17件、CQ5で2,253件中8件がガイドラインを作成するための最終的な文献として選定されました。5つのCQにおける主要解析では、LLMを用いたスクリーニングの感度は0.75(95%信頼区間[CI]、0.43-0.92)、特異度は0.99(95% CI, 0.99-0.99)でした。LLMの特徴として、人間が入力する命令文(コマンドプロンプト)によってLLMの作業内容が変化することが報告されています。本研究において、LLMにおける作業の質が向上するようにコマンドプロンプトを修正したところ、感度は0.91(95% CI, 0.77-0.97)に上昇し、特異度はほとんど低下しませんでした(0.98;95% CI, 0.96-0.99)。
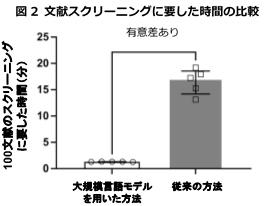
2.大規模言語モデルを用いた文献スクリーニングの作業時間の短縮
・LLMを用いた文献スクリーニングは、2~4人のガイドラインメンバーが人力で文献スクリーニングを行う従来の方法では17.2分かかっていた100件の文献スクリーニング時間を、約1.3分に短縮しました(平均差 −15.25分、95% CI, −17.70~−12.79)(図2)。
■今後の展開
今回の結果から、LLMを用いた文献スクリーニングはある程度の正確性を有していること(許容できる感度と非常に高い特異度)がわかりました。また、文献スクリーニングにかかる時間を大幅に短縮しました。この新しい文献スクリーニングの方法は、システマティックレビューの効率を向上させ、作業負担を軽減する可能性があります。
現在様々なLLMの開発が行われており、その性能や機能は日進月歩です。今後発表される改良版のLLMを用いることによって、文献スクリーニングの精度がさらに高まることが予想されます。また、今回の研究の中で検討したコマンドプロンプトは学問として発達途上にあるため、今後の知見によってLLMを用いた作業内容の正確性が大いに高まる可能性もあります。このようにLLMは今後さらに文献スクリーニングの精度や作業負担を改善する可能性があり、注目されていく分野であると考えられます。今回検討したのは敗血症の分野のみの文献検索でしたが、その他の医学分野においてもLLMを用いた文献スクリーニングの応用が期待されます。医療従事者の作業負担を減らしながら、より良い診療ガイドラインを作成するために、今後もAIを活用した作業の効率化につながる取り組みを続けていきます。
■用語解説
注1)大規模言語モデル(LLM):膨大な文章データを学習して、人間のように文章を理解したり作成したりするAI技術。ChatGPTはその一例で、質問に答えたり、文章を生成したりすることができる。
注2)医師の働き方改革:長時間労働の是正や、有給休暇の取得促進、多様な働き方の実現を目指した医師の労働環境の改善を目的とした一連の取り組み。
注3)日本版敗血症診療ガイドライン:敗血症は、感染症が原因で全身に強い炎症が起こり、命に関わる状態になる病気。本ガイドラインは、世界の専門家が集まって作成した、敗血症診療ガイドライン ’Surviving Sepsis Campaign Guidelines 2021’ を参考にして日本の現状に沿って作成したもの。
注4)ゴールドスタンダード:特定の疾患や条件の診断、治療、評価において最も信頼性が高いと認められている方法または基準。医学や科学の分野で広く用いられ、最も確かな証拠に基づく選択肢として推奨される。
注5)感度:ある検査が病気を持っている人を正しく見つけ出す能力を指す。感度が高いほど、病気を見逃さないという意味であり、例えば、感度が100%であれば、病気を持っている人を全員見つけ出すことができる。
注6)特異度:ある検査が病気を持っていない人を正しく除外する能力を指す。特異度が高いほど、健康な人を誤って病気だと判断する可能性が低いことを意味する。例えば特異度が100%であれば、健康な人を全員正しく健康だと判断することができる。
■論文情報
題名: Performance of a large language model in screening citations
著者名: Takehiko Oami, Yohei Okada, Taka‑aki Nakada
掲載誌: JAMA Network Open
企業プレスリリース詳細へ
PR TIMESトップへ